1. 사전 용어
본문을 읽기전에 본문에서 표현된 "정합성이 깨졌다","손상되었다." 라는 뜻은 아래 내용과 같다.
오라클의 블럭단위 : 8KB
OS의 블럭단위 : 4KB
# 오라클의 Datafile을 OS의 cp 명령으로 원하는 장소에 복사하는 상황이 있다 가정하자.
[1] OS에서 cp명령으로 Oracle datafile을 원하는 특정장소에 복사를 수행하려한다.
[2] cp 명령이 수행될때 OS의 블럭단위는 4KB이기 때문에 오라클의 Datafile을 cp할때, 4KB씩 복사할것이다.
[3] cp 명령이 수행되며 특정 A라는 Oracle 8KB짜리 블럭을 복사한다 가정한다.
[4] A라는 Oracle 8KB짜리 블럭이 OS에 의해 4KB로 쪼개져 전체 4KB블럭 두개중(4KB*2=8KB) 앞에 하나의 블럭만
복사가 수행됬다.
[5] 그 다음 4KB블럭 두개중 나머지 마지막 4KB블럭을 복사하려던 참에, 마침 Oracle 사용자가 쿼리를 입력하였고,
해당쿼리로 인해 마지막 4KB블럭안에 있는 데이터가 변경이 되었다.
[6] Oracle 사용자가 입력한 쿼리로 인해 데이터 변경이 일어난 다음, OS가 4KB블럭 두개중 뒤의 나머지 하나의
블럭을 복사하였다.
[7] Oracle의 입장에서는 Block단위는 8KB이며, OS의 4KB단위의 블럭이 2개가 합해진 8KB를 하나의 블럭으로
인식한다.
위의 [1]~[6] 과정에서 오라클 8KB전체 블럭중 앞에 복사된 4KB블럭과 변경이 가해진후 복사된 4KB블럭은
Oracle입장에서 서로 하나의 블럭으로써 합해져 취급되는데 각 4KB블럭마다 담겨져 있는 Data의 시간대가 일치하지
않게된다. 이를 아래 본문에서, "정합성이 깨졌다","손상되었다"라고 표현할 예정이다.

2. 잘못된 상식
아래글은 많은 사람들이 알고 있는 잘못된 상식을 작성한 글이다.
BEGIN BACKUP을 수행도중 Database에 들어오는 DML 쿼리에 대해 데이터들이 변경이 가해졌고,
COMMIT이나 CHECKPOINT가 발생할 때, 변경된 내용들은 Datafile의 Data block에 적용되지 않고,
REDO LOG나 Archive 파일에 변경된 데이터가 Chage vector ( A -> B ) 형식으로 기록된 다음 END BACKUP을
수행할 때 REDO LOG나 Archive 파일에 Chage vector ( A -> B ) 형식으로 기록된 변경 데이터분 내용들이
Datafile( Datablock ) 에 적용된다.
BEGIN BACKUP과 END BACKUP 사이에 외부에서 쿼리로 수행한 명령들에 대해
변경된 내용들은 Datafile의 Data block에 기록되지 않고, REDO LOG의 REDO REDO RECORD에 기록이 되기 때문에
cp명령으로 복사중인 Datafile에 변경을 가하지 않고, Datafile의 손상없이 안전하게 cp명령을 사용해, OS level에서
Database 파일을 복사 할수 있다.
또 END BACKUP을 수행한 즉시, REDO LOG의 REDO REDO RECORD에 기록된 내용들이 바로 Datafile에 적용이 되며,
사용자들이 백업도중 입력한 데이터들은 손실되지 않고, DB에 저장이 되어, 백업이 끝난 후에 Data에 대한 정합성을
만족한다. 이러한 BEGIN/END BACKUP 프로세스는, 사용자가 cp명령으로 Datafile의 백업을 수행하는 도중에
서비스에서 DB에 입력/수정 되었던 데이터들이 END BACKUP과 REDO LOG 또는 ARCHIVE LOG의
Chage vector 적용을 통해 Datafile들에 적용이 되므로 서비스를 운영하며 동시에 백업을 받을수 있는
HOT BACKUP 수행이 가능하게 하는 프로세스이다.

위의 말대로,
사용자들이 BEGIN BACKUP과 END BACKUP 사이에 요청한 DML, 변경분에 대한 내용들이, Datafile에 없고, Chage vector ( A -> B ) 형식으로 REDO RECORD 형태로만 있다면,
BEGIN BACKUP과 END BACKUP 사이에 변경한 내용들은 Datafile에 적용되어 있지 않기 때문에
BEGIN BACKUP과 END BACKUP 사이에 변경한 내용이 조회가 불가능할 텐데, 어떻게
BEGIN BACKUP과 END BACKUP 사이에 변경한 내용을 조회하여 서비스를 온전히 유지할수 있을까?
BEGIN BACKUP과 END BACKUP 사이에 변경한 내용중 조회한 내용에 대해서만 REDO RECORD에 내용을
Datafile에 적용하여, BEGIN BACKUP과 END BACKUP 사이에 변경한 내용을 사용자들이 온전하게 볼수 있는것일까?
그렇다면 Datafile에 변경이 일어날것이고, cp명령으로 복사하는 도중 Datafile에 변경이 일어나 Datafile이 손상된 채로 복사가 되게 됨으로 BEGIN BACKUP과 END BACKUP을 안전하게 수행하지 못하게 될수 있다.
즉, 위의
"BEGIN BACKUP을 수행도중 Database에 들어오는 DML 쿼리에 대해 데이터들이 변경이 가해졌고,
COMMIT이나 CHECKPOINT가 발생할 때, 변경된 내용들은 Datafile의 Data block에 적용되지 않는다." 라는 말은
잘못된 내용이다.
3. 올바른 상식
BEGIN BACKUP을 수행도중 Database에 들어오는 DML 쿼리에 대해 데이터들이 변경이 가해졌고,
COMMIT이나 CHECKPOINT가 발생할 때, 쿼리에 의해 변경되는 데이터들은 BEGIN BACKUP 이전과 동일하게
Datafile의 Data block에 입력/수정이 된다.
REDO RECORD ( Chage vector ( A -> B ) )들도 BEGIN BACKUP 이전과 동일하게 REDO LOG 또는 ARCHIVE 파일에
기록이 된다. 이와 동시에 BEGIN BACKUP 이후 사용자가 입력한 쿼리로인해 변경이 가해진 블럭들은
처음 변경이 가해졌을 때만 변경된 블럭과 함께, Chage vector ( A -> B ) 형식이 같이 REDO LOG나 ARCHIVE FILE에
기록된다.
그 이후에 또, (앞서 변경이 가해졌고, REDO RECORD에 기록이 됬던 블럭)동일블럭에 변경이 가해진다면,
그때는 변경이 가해진 블럭을 제외하고 평소처럼 Chage vector ( A -> B ) 형식만 REDO LOG나 ARCHIVE FILE에
기록된다. 또한 Data block header가 아닌 Datafile header에는 CHECK POINT SCN이 BEGIN BACKUP 시점의 SCN값으로 고정된 채 증가하지 않고, END BACKUP 명령 수행 이후 평소처럼 CHECKPOINT 발생시
CHECKPOINT SCN이 증가한다.

이렇게 되면 사용자가 BEGIN BACKUP을 수행하고, 사용자가 cp명령으로 Datafile들을 복사하여 백업을 받을 때,
분명히 cp명령을 수행하여 Datafile(Data block)을 복사하는도중, 복사하는 Datafile(Data block)에 대해
서비스 쿼리(DML)에 의해 변경되는 Data block이 발생할 것이다, 이는 복사 시작지점을 기준으로 데이터 정합성이
깨져버린 백업본이 될것이다.
그럼 이 데이터 정합성이 깨져버린 백업본을 복구를 할때는 어떻게 복구를 하는가?!
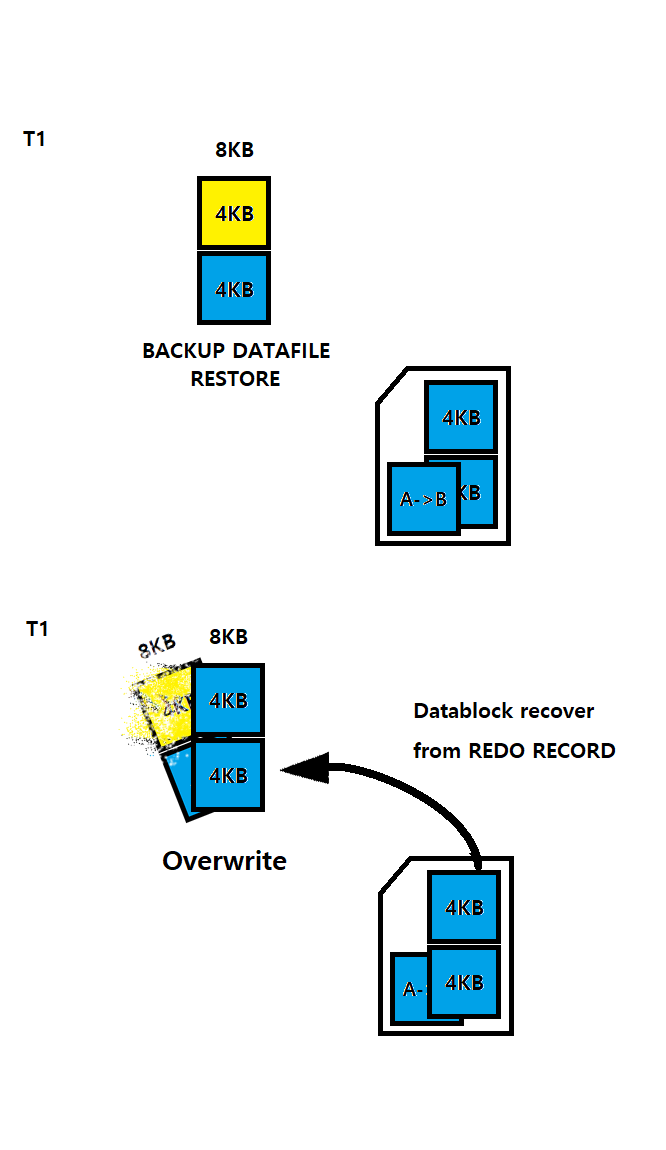
복구 할 때는 일반적인 상식처럼 백업 Datafile( 정합성이 깨져버린 Data block )위에 ARCHIVE LOG들을 적용시켜 recovery를 수행한다. 다만 ARCHIVE LOG들( REDO LOG : REDO RECORD )에 들어있던 "BEGIN BACKUP 이후 변경이
처음 가해진 블럭"을 Datafile( 정합성이 깨져버린 Data block )에 덮어쓰기 하며
cp명령을 수행하는 도중 Data가 변경되었던 정합성이 깨져버린 블록을 대체하며 초기화 시켜준다.그리고 초기화된 블럭에 Chage vector ( A -> B ) REDO record를 적용시켜 복구를 시켜준다. 이렇게 된다면, cp명령을 수행하는 도중 Data가 변경되었던 ( 정합성이 깨져버린 ) Data block에 대해 정합성을 맞춰주어 온전한 백업 복구데이터가 될것이다.
또한 사용자들이 BEGIN BACKUP과 END BACKUP 사이에 요청한 DML, 변경분에 대한 내용들이, Datafile에 평소처럼 적용이 되기 때문에 온전한 DB 서비스를 제공하며, HOT BACKUP을 수행할수 있을것이다.
4. 결론
"3. 올바른 상식" 에 의하면,
BEGIN BACKUP과 END BACKUP을 사용해 cp명령으로 Database를 백업하였을때,
해당 백업본을 RESTORE하기 위해서는 반드시 아래 두 항목의 파일이 필요하다.
- BEGIN BACKUP과 END BACKUP 사이에 생성된 Archive파일
- END BACKUP 직후 생성된 Archive파일
Archive 파일은 cp 명령으로 Datafile 복사도중 사용자들이 입력한 DML쿼리로 인해 정합성이 깨져버린 블록을
복구하는데 반드시 필요하기 때문이다.
만약 백업본 복구시 Archive파일 없이 Datafile만 RESTORE하여, 백업복구를 수행하려 한다면, 반드시 Mount 단계에서
Open 단계로 올릴때, 아래 오류로 인해 Database를 OPEN상태로 올리지 못할것이다.
------------------------------------------------------------------------------------------------------------------------------
*
ERROR at line 1:
ORA-01194: file 1 needs more recovery to be consistent
ORA-01110: data file 1: '/u01/oradata/ORCL/system01.dbf'
------------------------------------------------------------------------------------------------------------------------------
만약 BEGIN BACKUP과 END BACKUP사이에 아무런 DML 쿼리가 수행되지 않아, cp명령으로 Datafile을 복사도중
Datafile 변경이 일어나지 않았다면,
Archive 파일은 필요가 없을것이다. 다만, 서비스를 운영중에 수행하는 백업인 HOTBACKUP을 수행하는데, Datafile의
변경을 일으키는 DML이 일어나지 않을 가능성은 희박하다 생각된다.
5. 추가
BEGIN BACKUP과 END BACKUP으로 백업을 수행했을 때 Archive파일이 필요한 이유가 위와 별개로 추가로 또 있다.
보통 관리자들이 백업을 받을때, 아래와 같이 스크립트를 수행해 테이블스페이스 단위로 백업을 수행한다.
------------------------------------------------------------------------------------------------------------------------------
alter tablespace TBS1 begin backup;
!cp /u01/oradata/ORCL/tbs1_data.dbf
alter tablespace TBS1 end backup;
alter tablespace TBS2 begin backup;
!cp /u01/oradata/ORCL/tbs2_data.dbf
alter tablespace TBS2 end backup;
...
alter database backup controlfile to <file_location>;
------------------------------------------------------------------------------------------------------------------------------
위와 같은 스크립트가 수행될때 복사된 Datafile들과 Controlfile들은 아래 그림과 같이 파일헤더의 SCN이 각각 다르게
복사가 되 백업될것이다.

이렇게 백업된 Datafile과 Controlfile을 복구하려할 때 각각의 파일들은 제각각의 파일들은 다른 SCN을 갖고
있을것이다. Database를 Mount 단계에서 Open하려 할때는 Datafile들과, Controlfile들의 SCN이 모두 동일하게
일치해야 OPEN상태로 변경시킬수 있다. 제 각각의 파일들이 다른 SCN을 갖고 있기 때문에 recover명령으로 백업받은
Archive 파일들을 적용시켜 복원해주고, 각 파일중 낮은 SCN을 갖고있는 파일을 Archive 파일들을 적용시켜 SCN을
높혀주며, 각 파일중 가장 큰 SCN을 갖고 있는 파일의 SCN을 기준으로 모든 파일들의 SCN 맞춰줘 recovery를 수행하고, OPEN 상태로 Database를 변경할수 가 있다.
만약 tablespace 단위가 아닌 database단위로 begin backup을 수행하였을때는 아래 그림처럼

Controlfile을 제외한 모든 tablespace datafile의 SCN이 일치하기 때문에
복원시 Archive 파일을 사용해 SCN이 제일 높은 Controlfile의 SCN에 맞춰 모든 datafile들을 recovery 시켜주어야
할것이고, Controlfile을 재생성하여 복구하려한다면, 모든 datafile들의 SCN이 동일하기 때문에 Archive파일을
사용해 recovery를 해주지 않아도 될것이다. 다만, BEGIN BACKUP과 END BACKUP사이에 DML쿼리가 발생하지
않았다는 전제하이다.
DATABASE 단위로 백업을 받던, TABLESPACE 단위로 백업을 받던 BEGIN BACKUP과 END BACKUP사이에 DML쿼리가 발생했다면, Data block들의 정합성을 맞춰주기 위해 무조건 Archive파일을 통한 recovery가 필요하다.
참고 Page
http://esemrick.blogspot.com/2006/03/rman-is-absolutely-fuzzy.html
The Eric S. Emrick Blog: RMAN is Absolutely Fuzzy
This is a bit of a follow-on post to my The Pleasure of Finding Oracle Things Out post in which I spoke of some Oracle internal related mechanics relating to user-managed hot backups. In this post I want to focus on RMAN and how, subsequent to a restore of
esemrick.blogspot.com
http://esemrick.blogspot.com/2006/02/pleasure-of-finding-oracle-things-out.html
The Eric S. Emrick Blog: The Pleasure of Finding Oracle Things Out
Yesterday I was speaking with a colleague about various technical topics (as we frequently do) and he brought up a good question. He remembered reading that upon the issuance of the ALTER TABLESPACE END BACKUP command Oracle creates a redo record with the
esemrick.blogspot.com
https://positivemh.tistory.com/337
오라클 Hot backup시 변경이 발생한다면?
OS환경 : Oracle Linux6.8(64bit) DB 환경 : Oracle Database 10.2.0.4, 11.2.0.4 질문 : 안녕하세요 11g를 공부하고있는 학생입니다. hot backup 에서 data file을 alter .... begin backup 을 실행중일때, backu..
positivemh.tistory.com
https://login.oracle.com:443/oam/server/obrareq.cgi?encquery%3DcvwhCywHYmrnmS0oYmtlQuOctEmuZQaT1alNrLF2uRqcRQWo6NBqAjL7C8CP24BATYUD4fDZ8mbLgGMI5y0KHO5E9QLvcFPb0V3lslKc%2FwOP0y9UQrGul5v37PsxTI0QPufpLKOAgjFb3vH87xhTcYO8p93oX9gBHkQ8kvbwHZaae50Ue2Pzxxy4iyR4B84xpeKDI0pFQnDdSexsfKeQG5%2Bt15W2%2FxRiCrcnF38esBoBFdwUeXhSBjdza3pW0b3TVgLGYYNE80hyzpbGgLLweiVtP4cd%2BzVBCjpxM2Zss4t5jZOhVhkVWWuRPECaNxE%2BF66k%2Bpz3EPJZ0G8qqbCckWQRYRXDpxXjfuj6%2B8mYByxvcIr00kIRTHs2buY6EzGHdlPlCItZYNDPMe%2BtW9ffYlb6pEYZQf9ioUgt8MBJ35HQ%2FHo6sQPmwBbMB7y%2Fnu227ap7NGSPW8jb1HnrnKlYo4lLrysw9vG0aCGhA%2FREuQPXzqXqE3ltOhTJj34qXWA8tvjYYu4ZnZD%2BrOFE62M408S4J4e%2F9%2FXRpY9K1GTRFhNmwB%2BBlbgL2RnmhBlUMJOsPWqZZ5zSncb5J7I%2Fu8T%2BF9BXbLAO5yk2RTUjp%2FHV2%2FXH1EnHFPo%2BxVe%2FOPxjpABsiSspDLbJ50LqEww%2FOL8ejCFp0m4E%2F7UgAwSsyHmRTC1a2vIm6jPYh6%2FSIjsRYtK2FLba6ZJg8m%2Fgf5rvp3g1etrvk6EJR2CjyB7S0A6FVNI%3D%20agentid%3DcorpWebgates%20ver%3D1%20crmethod%3D2%26cksum%3Da1b6e54e0f350397ba6c41039d5370a84de78083&ECID-Context=1.005eK%5EHHI3O8XrKaETz0ES0002BS0066wW%3BkXjE
login.oracle.com:443
One danger in making online backups is the possibility of inconsistent data within a block. For example, assume that you are backing up block 100 in datafile users.dbf. Also, assume that the copy utility reads the entire block while DBWR is in the middle of updating the block. In this case, the copy utility may read the old data in the top half of the block and the new data in the bottom top half of the block. The result is called a fractured block, meaning that the data contained in this block is not consistent. at a given SCN.
Therefore oracle internally manages the consistency as below :
1. The first time a block is changed in a datafile that is in hot backup mode, the entire block is written to the redo log files, not just the changed bytes. Normally only the changed bytes (a redo vector) is written. In hot backup mode, the entire block is logged the first time. This is because you can get into a situation where the process copying the datafile and DBWR are working on the same block simultaneously.
Lets say they are and the OS blocking read factor is 512bytes (the OS reads 512 bytes from disk at a time). The backup program goes to read an 8k Oracle block. The OS gives it 4k. Meanwhile -- DBWR has asked to rewrite this block. the OS schedules the DBWR write to occur right now. The entire 8k block is rewritten. The backup program starts running again (multi-tasking OS here) and reads the last 4k of the block. The backup program has now gotten an fractured block -- the head and tail are from two points in time.
We cannot deal with that during recovery. Hence, we log the entire block image so that during recovery, this block is totally rewritten from redo and is consistent with itself at least. We can recover it from there.
따라서 복구하는 동안 이 블록(cp명령시 깨진블록)은 "REDO"에서 완전히 다시 꺼내와져 쓰여지고, 온전한 블럭과 일치하도록 전체 블록 이미지를 복구한 RESTORE 파일에 기록합니다. REDO에서 깨진블록을 복구 할 수 있습니다.
2. The datafile headers which contain the SCN of the last completed checkpoint are not updated while a file is in hot backup mode. This lets the recovery process understand what archive redo log files might be needed to fully recover this file.
To limit the effect of this additional logging, you should ensure you only place one tablepspace at a time in backup mode and bring the tablespace out of backup mode as soon as you have backed it up. This will reduce the number of blocks that may have to be logged to the minimum possible.
'Oracle > Theory' 카테고리의 다른 글
| PMD, 정책관리형 데이터베이스, 관리자관리형 데이터베이스, 서버풀 (0) | 2020.07.15 |
|---|

댓글